Using the “Modified JavaScript value”-step you can call functions in java script, like Math.max().

Notes about using Pentaho Data Integration and Apache Hop as Non-Programmer

Using the “Modified JavaScript value”-step you can call functions in java script, like Math.max().
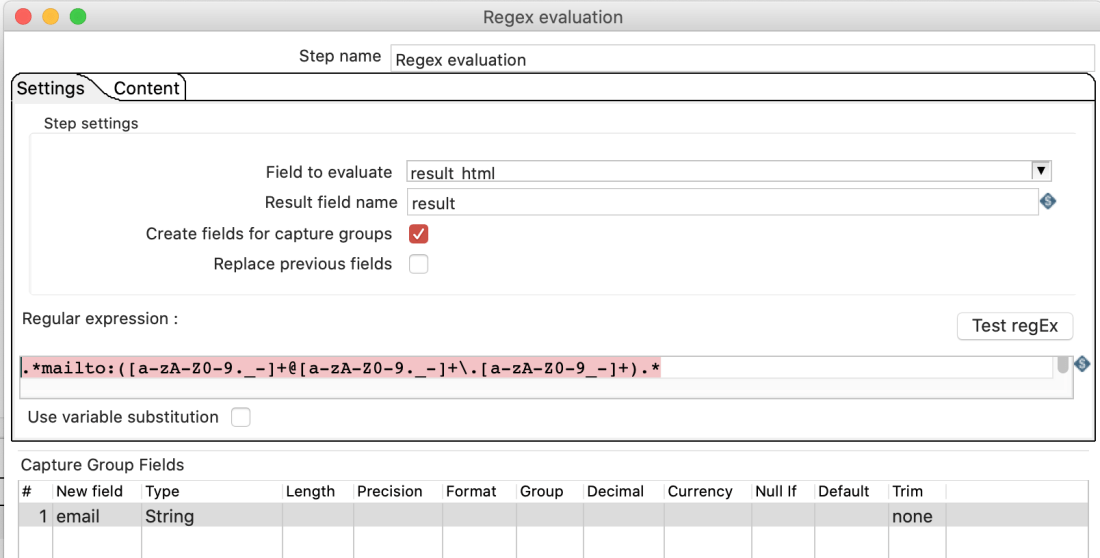
How to extract the email of the corresponding author of a publication, like: https://doi.org/10.1039/C7CS00709D with Pentaho Data integration?


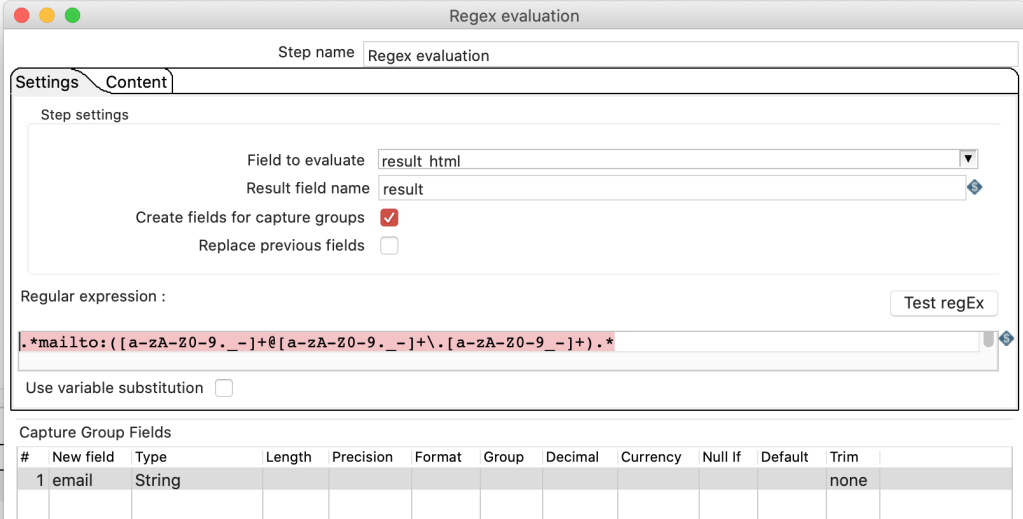

The first email appearing in the HTML will put into the filed email.
Alternatively the Online Service https://www.convertcsv.com/email-extractor.htm also provides a nice possibility to extract emails from several websites:


In the last post I created a sub-transformation with a “transformation executor” step. It works, but I had to look up the results from the sub-transformation in a later step. However, Pentaho Data Integration (PDI) however offers a more elegant way to add sub-transformation.
I will use the same example as previously.
In your sub-transformation you insert a “Mapping input specific” step at the beginning of your sub-transformation and define in this step what input fields you expect. At the end you add an “Mapping output specification” step, where you don’t have to specify anything.

So in the main transformation you can add the step “Simple mapping (sub-transformation)”.
In this step you can map the fields of the parent transformation to the expected fields that you have defined in the input step of the sub-transformation. If you use the same field names, PDI provides a nice auto-mapping feature in the step options: “Mapping…” -> “Guess…”
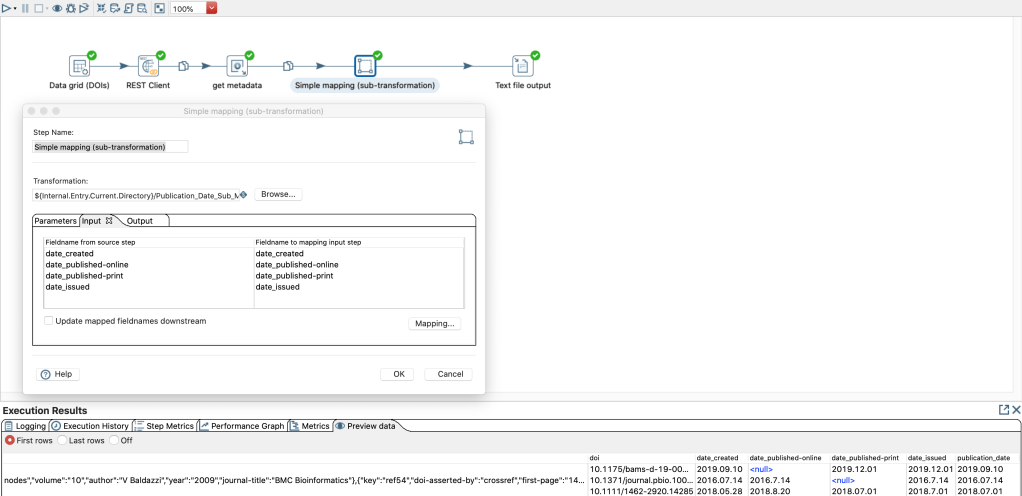
It is not necessary to specify the “Output” tab, because in this case all fields created in the sub-transformation become available in the following steps of the super/main transformation.
The advantage here is that the fields that you have not passed on to the sub-transformation are directly available in the following steps of the partial/main transformation.
