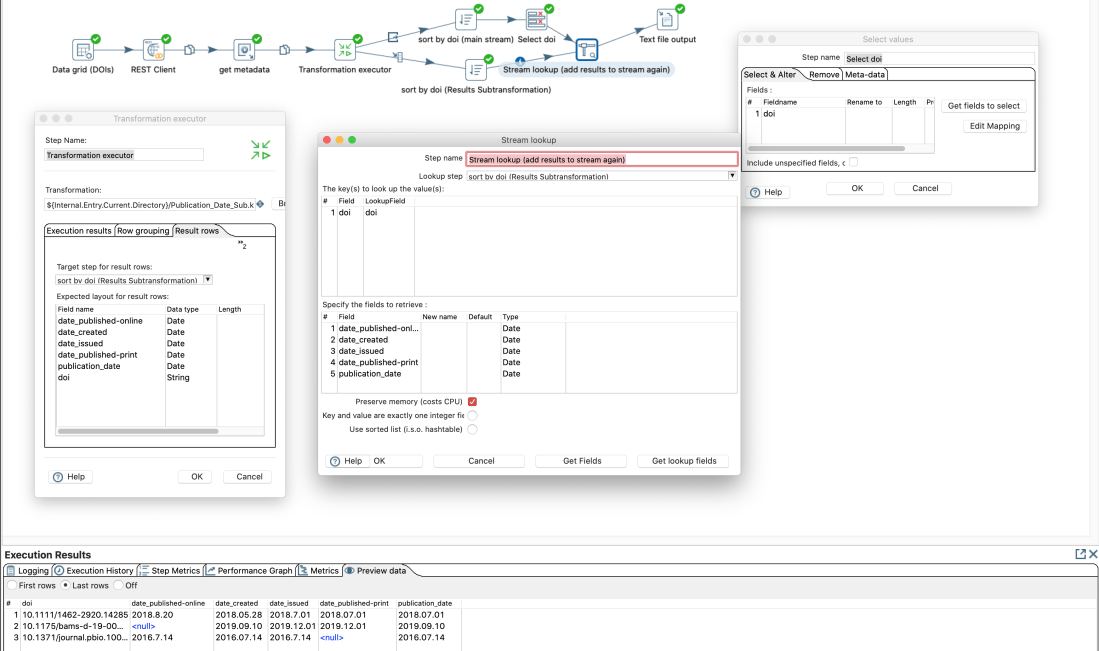
In the last post I created a sub-transformation with a “transformation executor” step. It works, but I had to look up the results from the sub-transformation in a later step. However, Pentaho Data Integration (PDI) however offers a more elegant way to add sub-transformation.
I will use the same example as previously.
a) Sub-Transformation
In your sub-transformation you insert a “Mapping input specific” step at the beginning of your sub-transformation and define in this step what input fields you expect. At the end you add an “Mapping output specification” step, where you don’t have to specify anything.

Publication_Date_Sub_Mapping.ktr
b) Parent/Main-transformation
So in the main transformation you can add the step “Simple mapping (sub-transformation)”.

In this step you can map the fields of the parent transformation to the expected fields that you have defined in the input step of the sub-transformation. If you use the same field names, PDI provides a nice auto-mapping feature in the step options: “Mapping…” -> “Guess…”
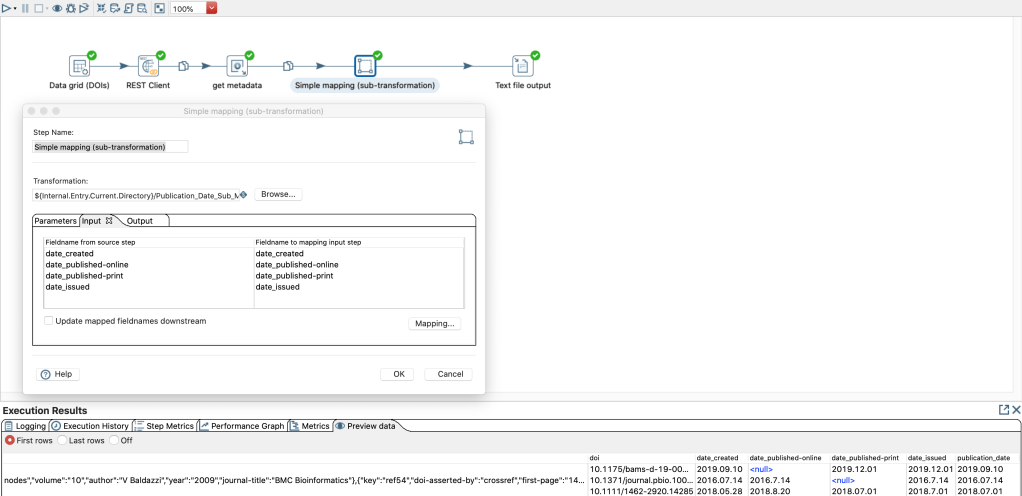
It is not necessary to specify the “Output” tab, because in this case all fields created in the sub-transformation become available in the following steps of the super/main transformation.
The advantage here is that the fields that you have not passed on to the sub-transformation are directly available in the following steps of the partial/main transformation.