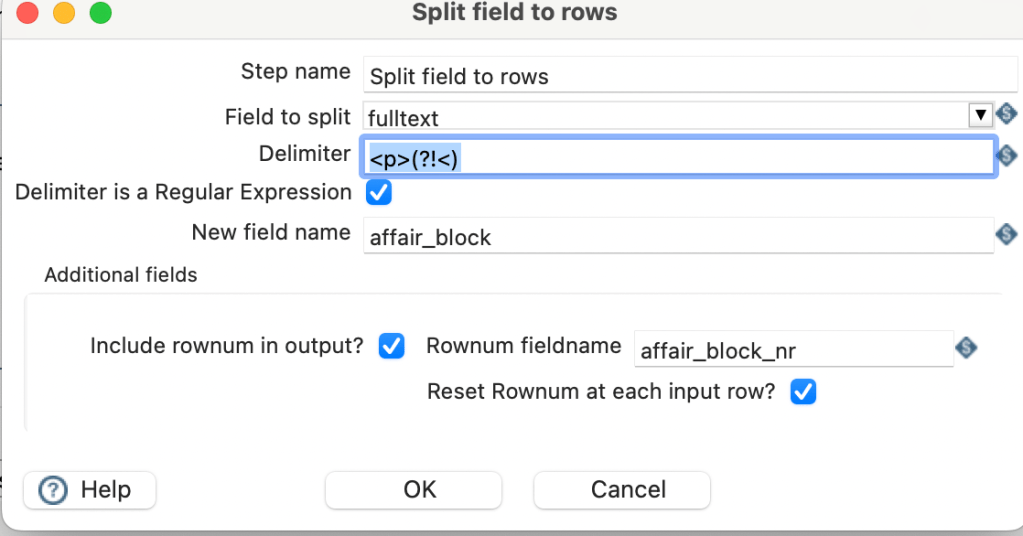
Sometimes you want to fil empty values in a row, with the last occurence of the colum, that is not null. Eg in the following example I want to fill rows 44-50 with the event_date “26.06.2023” an rows 53-54 with “28.08.2023”.
For that a simple java script can be used:
var event_date_new; if (event_date !== null) { event_date_new = event_date;}
This results in a new column with all dates filled
So for 2020 there are 542k entries. In order to download metadata data (or in my case just the DOI, date of DOI registration and the Elsevier internal ID) I’m using again the REST API of Crossref.
Actually a Crossref query is limited to provide max 1000 DOIs. Using cursors, it’s however to possible to loop further and get about 100k DOIs before the API times out. So in order to get all publications from 2020 I created a monthly batch based on the created date like:
In PDI I’ve created a job, that handles the cursor and repeats the transformation with the REST Query as long there is a new cursor coming back from Crossref.
It’s important that there’s a HTTP-Header like: “Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_5)”, otherwise the Pentaho Client will be routed to a error page.
Extracting data from abstract HTML
Elsevier makes it very easy to extract information about the article without going deep into the HTML-Structure of ScienceDirect. Within the HTML there’s a whole section with structured data in JSON:
Having the JSON data block separated from the rest of the HTML, we now can pass it to the JSON-input step. There is really plenty of information and much more than you would see via front end.
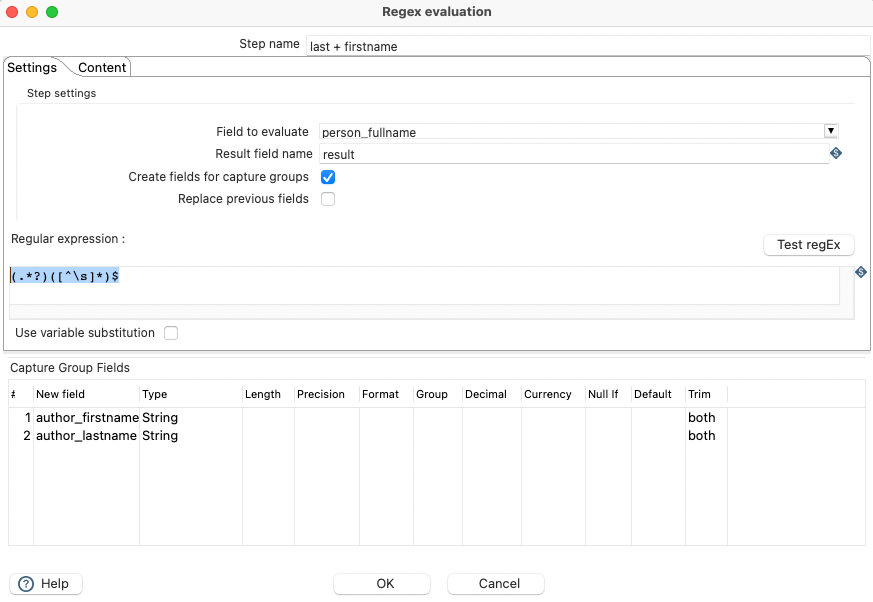
An author can have multiple labels/refids, emails, contributor-roles. In order to get those flat in a row separated by a coma, a group step can be used, while getting it back into the stream using the “stream lookup”-step:
Merge affiliations and authors
In a third step authors and affiliations are merged by the the label:
in order to get a list with authors and affiliations
Extracted authors and affiliations from Elsevier articles
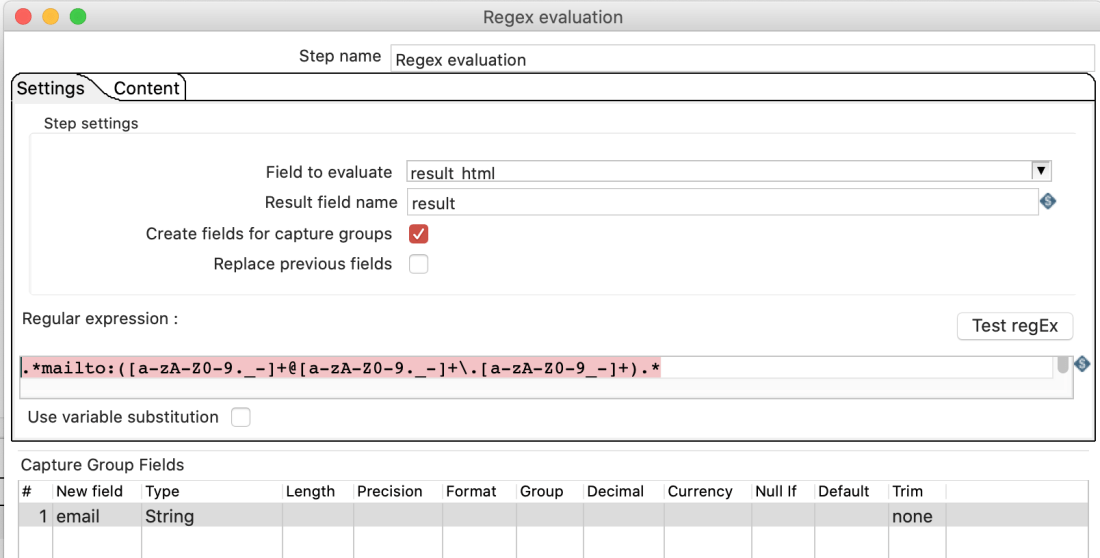
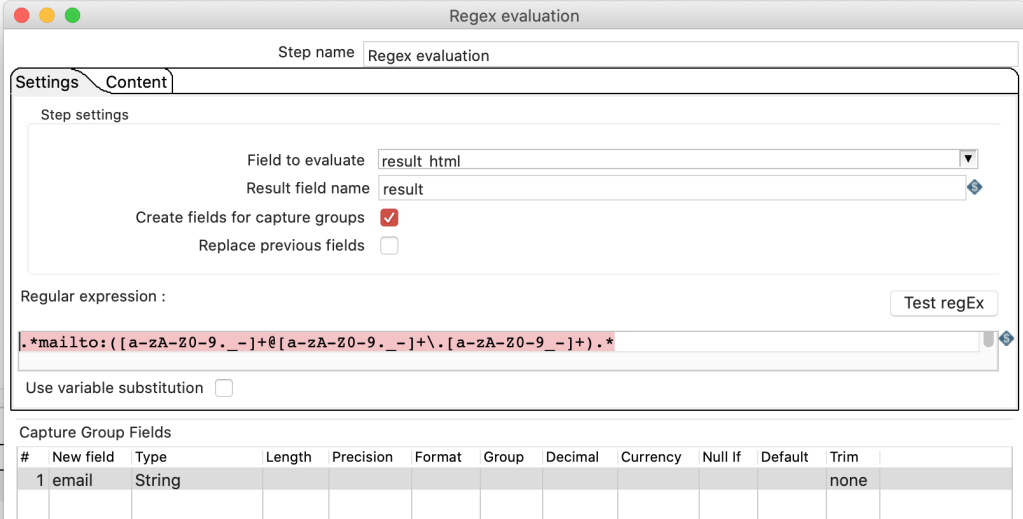
Alternatively to the “Replace in string”-Step, the “Modified JavaScript value”-Step can be used to replace something in a string. eg. here to replace a carriage return with a white space:
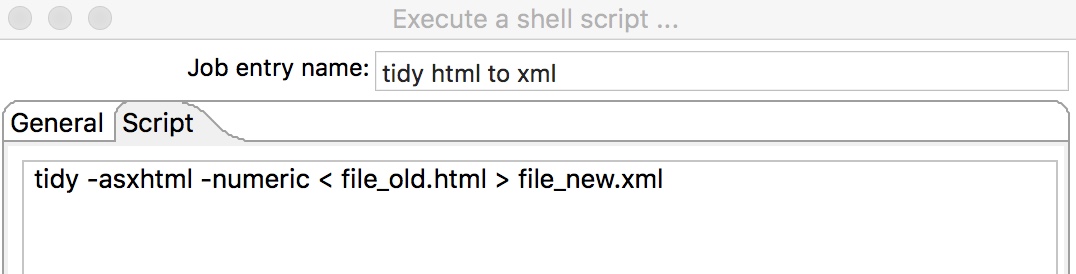
To trigger a shell script or a terminal command after a transformation, you have to create a job (it’s not available in a transformation). In the following scenario I wanted to transform a HTML-File to XML using tidy.
So I define a job, where the file is created and use the step “Execute a shell script…”