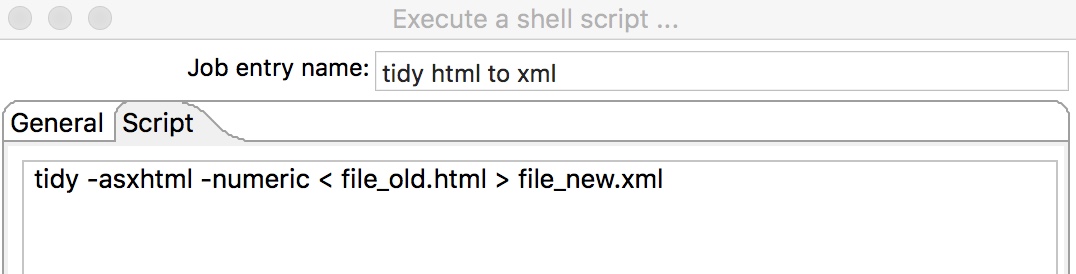
You can bundle a couple of steps as a transformation and call those steps in another transformation.
My scenario: determine publication date
I often use the Crossref Rest API to get information about publications. Depending on the publisher there are different kind of dates associated with a DOI and the dates can have different resolutions. Sometimes just a year or a year and a month.

In order to get always a specific publication date with the resolution YYYY.mm.dd I use a couple of steps and logic to determine the “relevant” publication date out from those different date fields.

To reuse those steps in different transformations without copying each time all these steps I can now save those steps as own transformation. Let’s add a “Get rows from result” and “Copy rows to result” at the beginning and and end this sub-transformation.

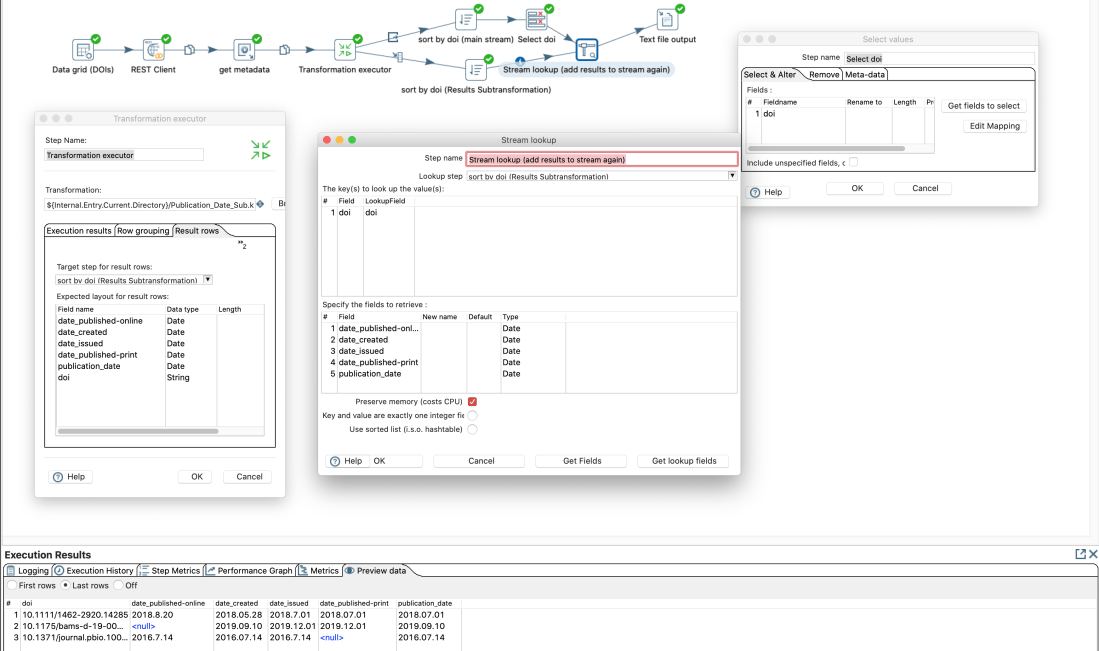
Then we can add a “Transformation executor” step in the main transformation. In this step we add the expected “fields” of the sub-transformation in the tab “Results row”
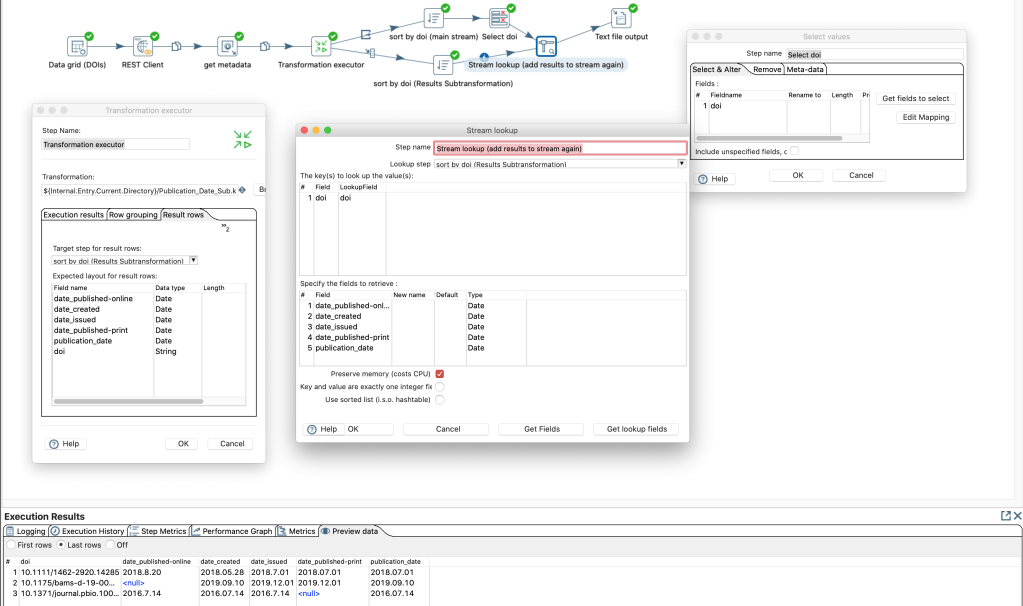
As output of a “transformation executor” step there are several options available:

There seems to be no option to get the results and pass through the input steps data for the same rows. Probably since the output of the sub-transformation can have more more or less rows than the input. Yet we can create a work-around by going on the the input data and add the results of the sub-transformation with a common (presorted) identifier. At the end we have the original data and the result of the sub-transformation combined.