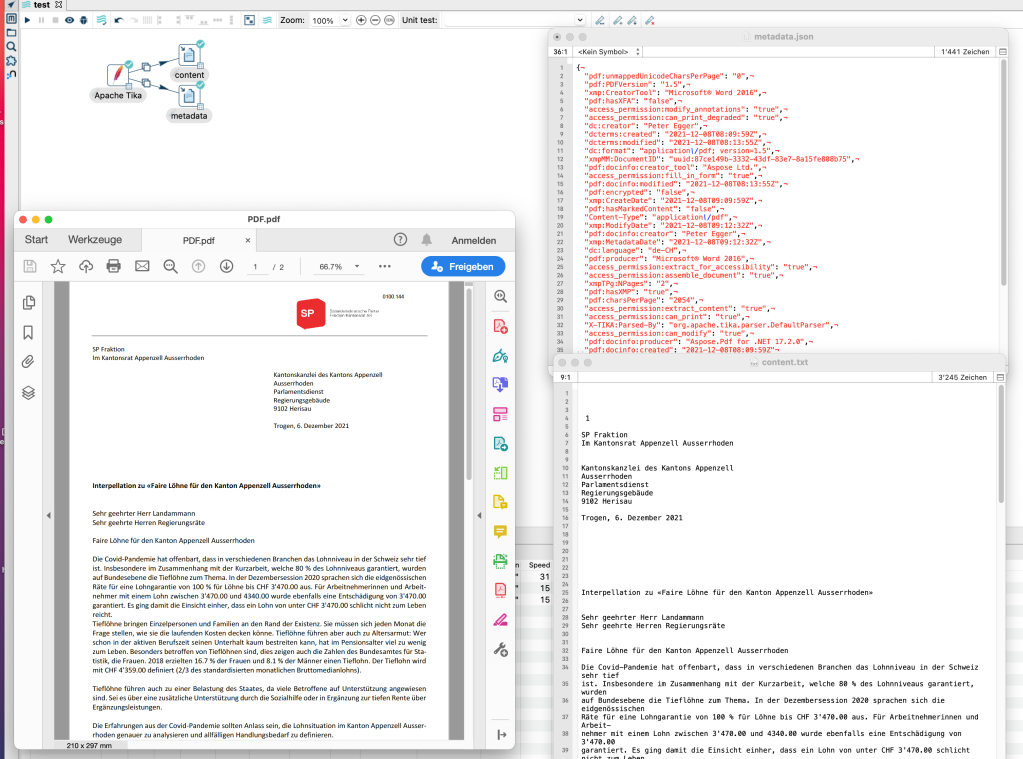
The recently released Apache Hop 1.1 version comes with a very handy new transform step, that allows you to extract the metadata and content of different fileformats like PDF using Apache Tika.
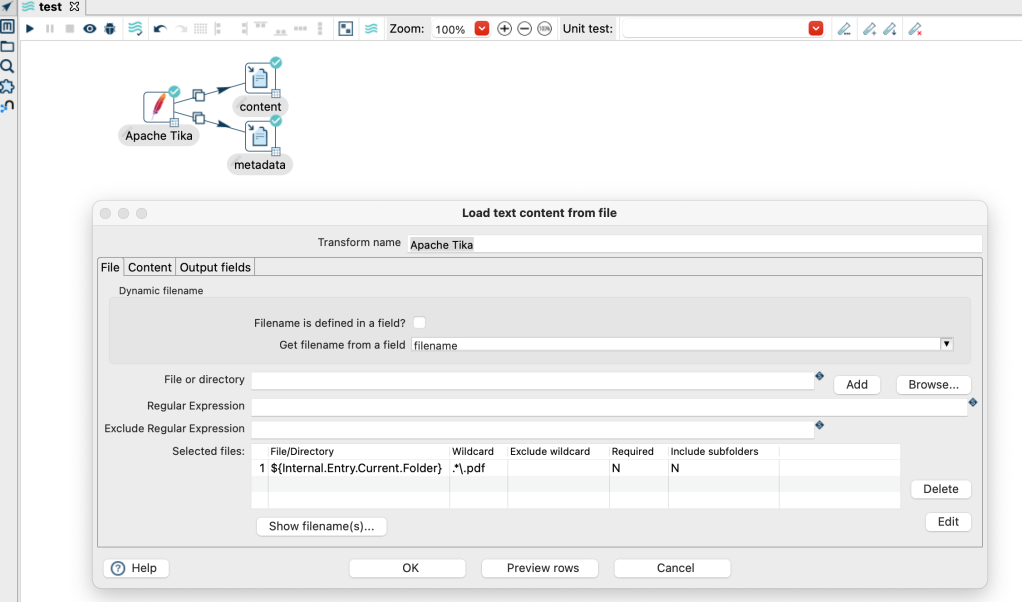
The transform step is available in a pipeline:
It allows you to output the content as Plain text, XML, HTML and JSON:
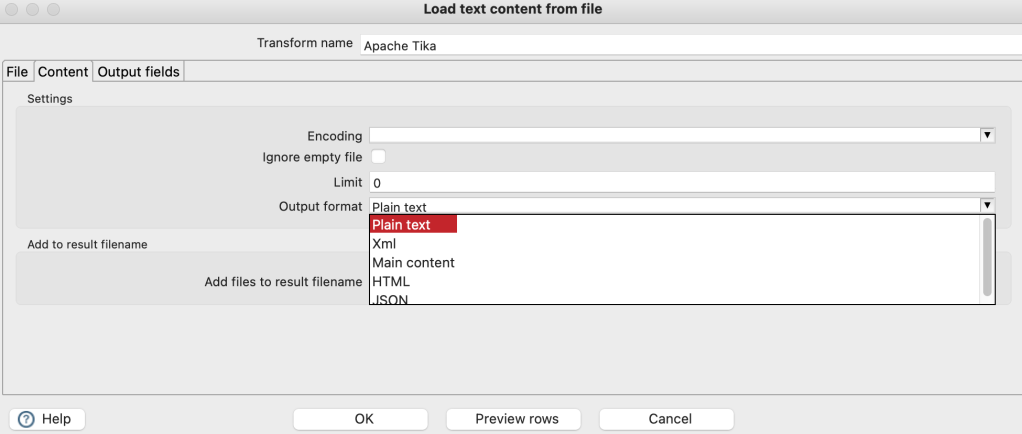
Output Options
Result: